Sprint 3
Planejamento
1. Objetivos e Duração
Duração:
04/09/2018 a 10/09/2018
2. Sprint Backlog
3. Pontuação da Sprint
4. Papéis
5. Pareamento
O foco do pareamento desta sprint foi um breve treino prático de produção de código dentro das políticas de desenvolvimento do repositório.
6. Riscos da Sprint
Os riscos indentificados nesta sprint foram:
Resultado
1. Sprint Review
Todas as tarefas referente a essa sprint foram concluídas com sucesso no tempo
estabelicido. Mesmo tendo a configuração de ambiente junto
com o treino prático de produção de código na mesma sprint houveram os três
cruds propostos. Além disso dados referentes as sprints passadas
foram coletados e utilizados na produção do velocity por sprint e do burndown
por sprint.
2. Sprint Retrospective
| Pontos Positivo | Pontos Negativos | Soluções |
|---|---|---|
| Feedback do monitor | Organização do backlog das sprints | Rever backlog de projeto/sprint até a release 1 |
| Funcionamento do pages | Organização na coleta das métricas | Organizar as métricas por sprint |
| Documentação mais formal | Documentação no drive | Migrar toda a documentação para o pages |
| Ambiente Django funcionando no Docker | Reunião não presencial | Realizar somente em ultimo caso reuniões não presenciais |
| Treinamentos | - | - |
| Pareamento entre MDS | - | - |
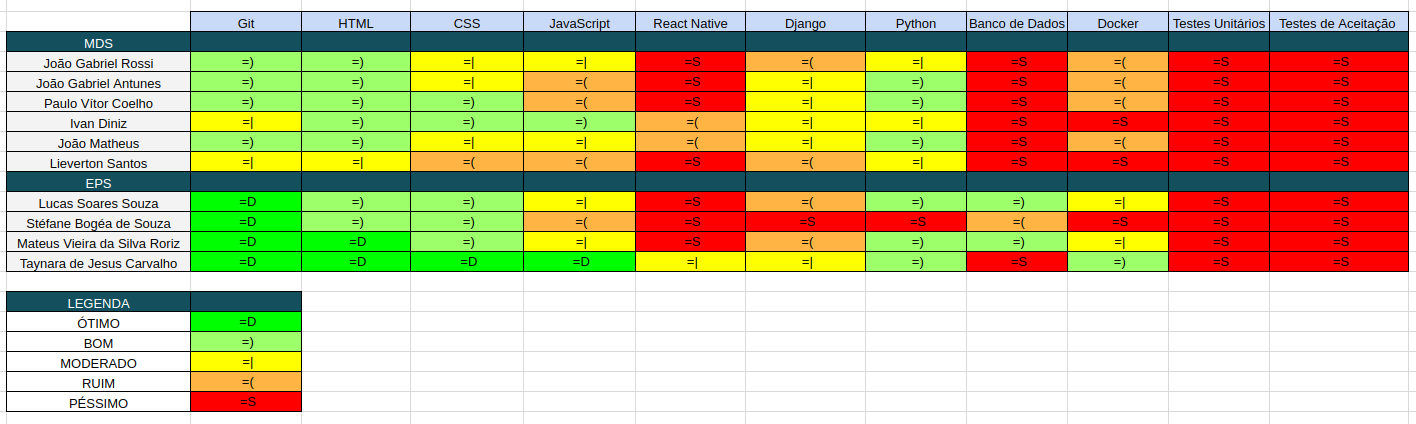
3. Quadro de Conhecimento
4. Burndown
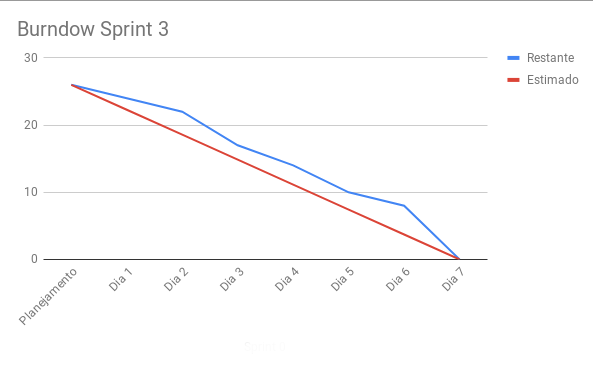
Primeiro burndown onde as entregas das tarefas foi realmente datada.
5. Velocity
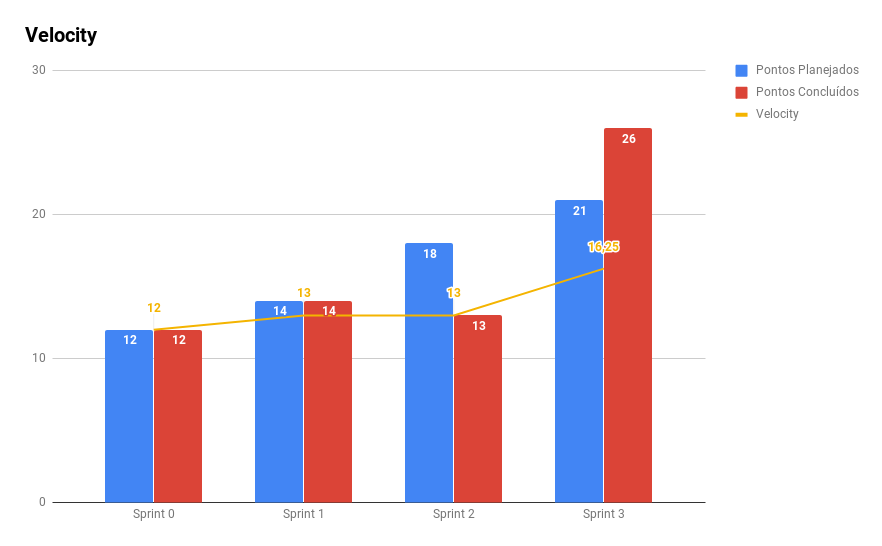
A pontuação efetuada foi maior do que a pontuação planejada pois recebeu os pontos de dividas técnicas da sprint anterior
6. Gráfico de Commit
7. Análise do Scrum Master
A sprint ocorreu sem grandes problemas ou necessidades de
solucionar ocasionais riscos.
Um dos objetivos da sprint foi a organização e padronização dos
documentos. Para tal
foram criados os templates de relatórios de sprints como também os templates do
velocity e burndown.
O burndown até essa sprint foi coletado diretamente numa tabela do google drive
entretanto a partir da
sprint 4 espera-se que tal coleta seja feita na ferramenta ZenHub. Já que tal
ferramenta pode verificar, com exatidão, a data
de cada entrega dentro de utilizando um KanBan adaptado ao projeto.
Os CRUD's produzidos nesta sprint não serão utilizados como código
para a release 1 pois a arquitetura
do sistema é a de microserviços e caso continuassemos com tal código o nosso
sistema acabaria por se tornar um projeto
em arquitetura monolítica. Por isso o código nessa sprint criado não irá para a
master se tornando, como esperado, um código de treino.
Sobre os riscos da sprint foi resolvido comenta-los tópico a tópico:
Configuração de Ambiente
A configuração de ambiente se tornou um risco nessa sprint pois
caso ela não houvesse sido
realizada a tempo atrasaria a entrega dos CRUDS. Para que isso não acontecesse
foi feita uma priorização
dentro da mesma sprint focando com que o ambiente docker fosse organizado antes
de qualquer tarefa. A
DevOps do projeto conseguiu resolver todo o ambiente inicial Django dentro do
container do Docker ainda no
primeiro da sprint o que permitiu que os desenvolvedores começassem a produzir.
Não conseguir recuperar dados de sprints passadas
Este risco foi considerado pois como os dados que haviamos
trabalhado nas sprints passadas
estavam todos no google drive não se sabia se eles haviam sido alterados ou
apagados acidentalmente. A medida
preventiva deste risco foi verificar o histórico de todos os documentos no
drive além de fazer uma análise
de cada issue e respectiva pontuação com cada gráfico de burndown ou velocity
previamente criado.
Pontuação alta de sprint backlog
Como dito no relatório da sprint 2, mesmo havendo dívidas técnicas
na sprint pode-se perceber que
a equipe conseguiria produzir mais pontos do que a médida dada pelo velocity
até então. Isso ocorreu pois o motivo
da tarefa se tornar dívida técnica foi justamente ela ser um bloco de grandes
tarefas e sua má pontuação. Logo houve
mais uma tentativa de possuir um backlog com uma pontuação maior do que a
anterior e, neste caso, houve um significativo
sucesso onde a dívida técnica da sprint passada foi entregue como também todos
os outros pontos da sprint atual.